Machine Learning for Beginners: An Introduction to Neural Networks
A simple explanation of how they work and how to implement one from scratch in Python. The contents of this document are taken from Victor Zhou's blog.Here’s something that might surprise you: neural networks aren’t that complicated! The term “neural network” gets used as a buzzword a lot, but in reality they’re often much simpler than people imagine.
This post is intended for complete beginners and assumes ZERO prior knowledge of machine learning. We’ll understand how neural networks work while implementing one from scratch in Python.
Let’s get started!
1. Building Blocks: Neurons
First, we have to talk about neurons, the basic unit of a neural network. A neuron takes inputs, does some math with them, and produces one output. Here’s what a 2-input neuron looks like:
A 2-input neuron
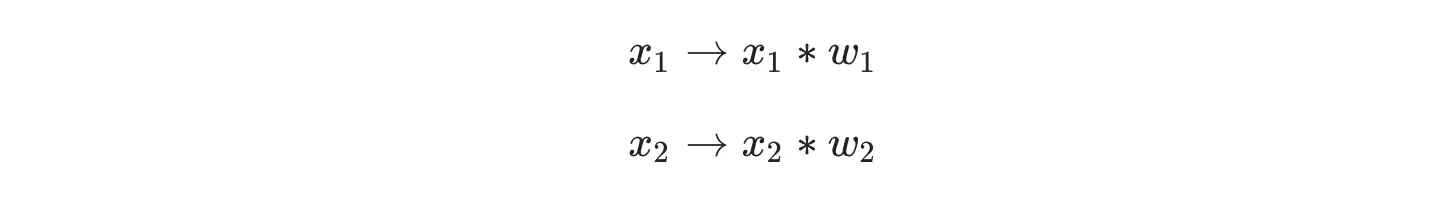 Next, all the weighted inputs are added together with a bias (represented by the green sum sign in the picture above).
Next, all the weighted inputs are added together with a bias (represented by the green sum sign in the picture above).
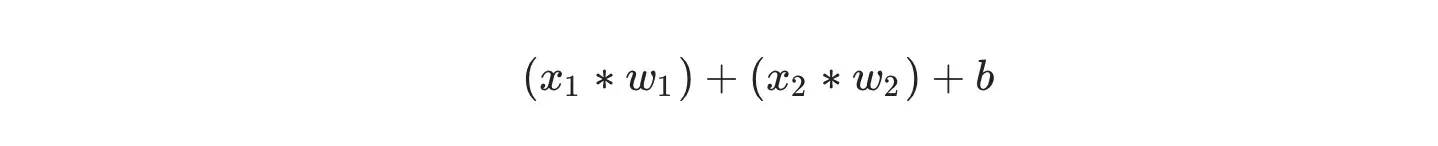
Finally, the sum is passed through an activation function:
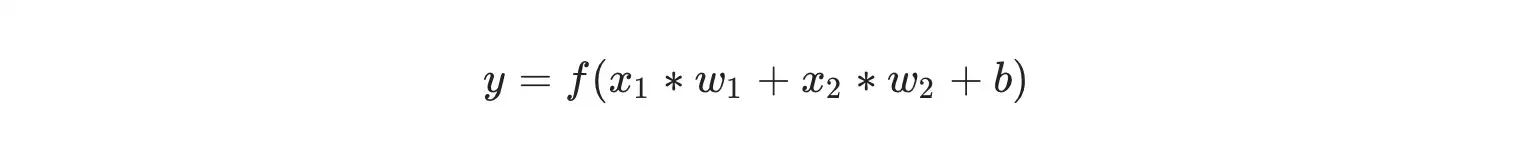
The activation function is used to turn an unbounded input into an output that has a nice, predictable form. A commonly used activation function is the sigmoid function:
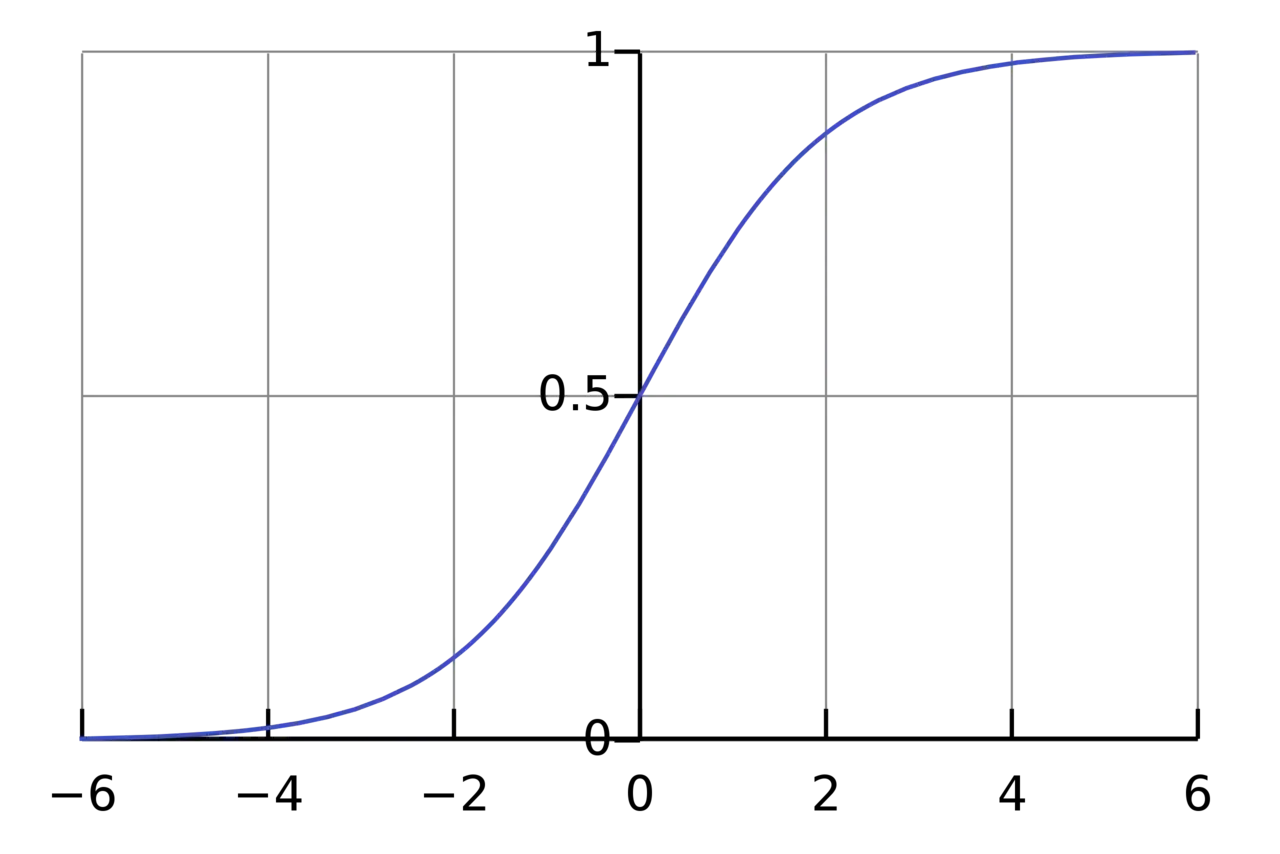
A sigmoid function transforms all numbers to be between 0 and 1
A Simple Example
Assume we have a 2-input neuron that uses the sigmoid activation function and has the following parameters: w = [0, 1] and b = 4.w=[0, 1] is just a way of writing w1=0, w2=1 in vector form. Now, let’s give the neuron an input of x=[2, 3]. We’ll use the dot product to write things more concisely:
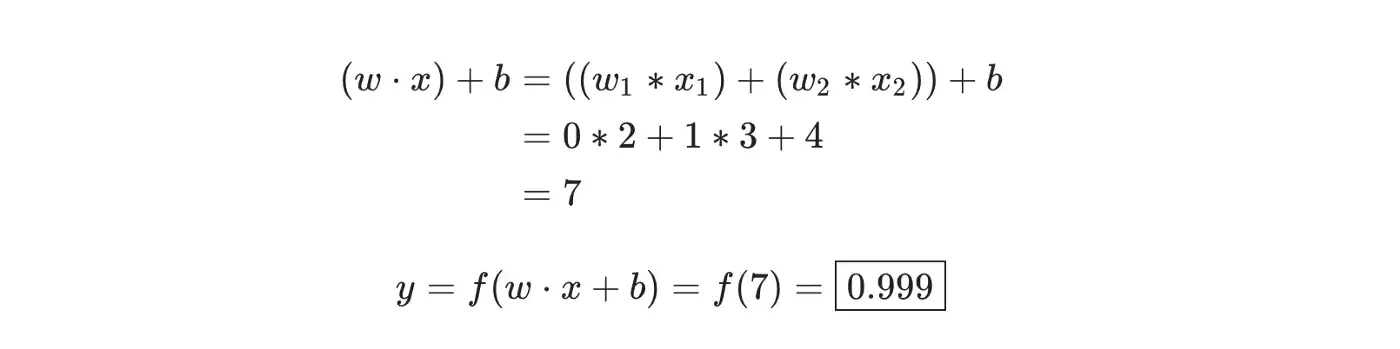
A worked example of a neuron being applied to input x=[2,3]. The weights of the neuron are w=[0,1] , and the bias b=4.